
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- HTTP
- Type Challenge
- 굿바이 2024년
- 백엔드
- 이펙티브 타입스크립트
- 코딩테스트
- typeorm
- 회고록
- microsoft azure openai
- 타입챌린지
- 월간cs
- configmodule
- 2024년 회고록
- mysql boolean
- 타입스크립트
- network
- 와글와글
- npm
- 스터디
- type-safe configservice
- nestjs
- TypeScript 타입챌린지
- configservice
- 회고
- typescript type challenge
- 타입 챌린지
- 해커톤
- node.js
- TypeScript
- mysql
- Today
- Total
iamkanguk.dev
[Network] HTTP 기본개념 본문
해당 포스팅은 김영한님의 모든 개발자를 위한 HTTP 웹 기본 지식 강의를 토대로 작성되었습니다.
HTTP (HyperText Transfer Protocol)
서버와 클라이언트가 서로 데이터를 주고받기 위해 사용되는 통신 규약이다. 웹문서(hypertext) 간에 링크를 통해 연결할 수 있는 프로토콜이고, 문서 뿐만 아니라 다양한 종류의 데이터들을 폭 넓게 전송할 수 있다. 심지어 서버 간의 통신에서도 HTTP를 사용하고 있다.
HTTP의 역사
(1) HTTP/0.9 - 1991년
GET 메서드만 지원했고, HTTP 헤더는 존재하지 않았다.
(2) HTTP/1.0 - 1996년
Method와 Header, 그리고 상태코드가 추가되었다.
(3) HTTP/1.1 - 1997년
현재 가장 많이 사용하고 있는 버전이며 대부분의 기능이 추가되었다. 지정한 Timeout 동안 연속적인 요청 사이에 Connection을 닫지 않는다.
(4) HTTP/2.0 - 2015년
HTTP 1.1의 성능이 개선되고 확장되었다. Multiplexing을 지원하고, 파싱 및 전송속도를 증가시켰다. 그리고 HPACK 압축을 지원하면서 헤더 중복값을 개선하였다.
(5) HTTP/3.0 - 2019년 + ing
TCP 대신에 UDP를 이용한 QUIC 프로토콜을 사용하고 있다. 기존 TCP의 고질병인 지연시간(RTT)를 해결하였다.
HTTP 기반 프로토콜
HTTP/1.1과 HTTP/2.0은 TCP 프로토콜 위에서 동작을 하고 있다. 하지만 HTTP/3.0은 UDP 프로토콜 기반으로 개발이 되어있다. 기본적으로 TCP는 3-way handshake와 이외의 다른 것으로 인해 속도가 느린 편이다. 그래서 3.0 버전에서는 UDP 프로토콜 위에 애플리케이션 단계에서 성능을 최적화하도록 설계가 되고 있다.

h2는 2.0 버전을 의미한다. h3은 확인해보지 못했지만 이처럼 다양한 버전들이 사용되고 있고 급속도로 커지고 있다.
참고로 구글에서는 h3를 적용하고 있더라! 궁금하면 한번 구글에서 아무거나 검색해서 개발자 도구를 켜보자.
HTTP의 구조: 클라이언트-서버 구조
HTTP 통신은 클라이언트(Front-End)와 서버(Back-End)로 나누어진 구조로 되어있다. 우리가 잘 알다시피 클라이언트에서 요청을 하면 서버에서 요청을 처리하고 응답하는 것이다.
과거에는 클라이언트와 서버를 구분하지 않았다고 한다. 하지만 왜 분리를 하게 되었을까? 각자의 역할에 집중할 수 있기 때문이다.
클라이언트에서는 복잡한 비즈니스 로직이나 데이터를 다룰 필요가 없고 UI를 그리는데 집중할 수 있다. 반대로 서버에서는 복잡한 비즈니스 로직, 데이터를 다루는데만 집중하면 된다. 예를 들어, 만약 트래픽이 급증해서 고도화가 필요하다고 생각되는 경우에는 서버만 개선하게 되면 문제를 해결할 수 있다.
결론은 클라이언트와 서버를 구분하는 것은 각자의 책임을 나눠 각자 책임에만 집중하고, 클라이언트와 서버 양쪽이 각각 독립적으로 고도화 할 수 있다는 점이다.
HTTP의 무상태성 (Stateless)
(1) Stateful (상태유지)
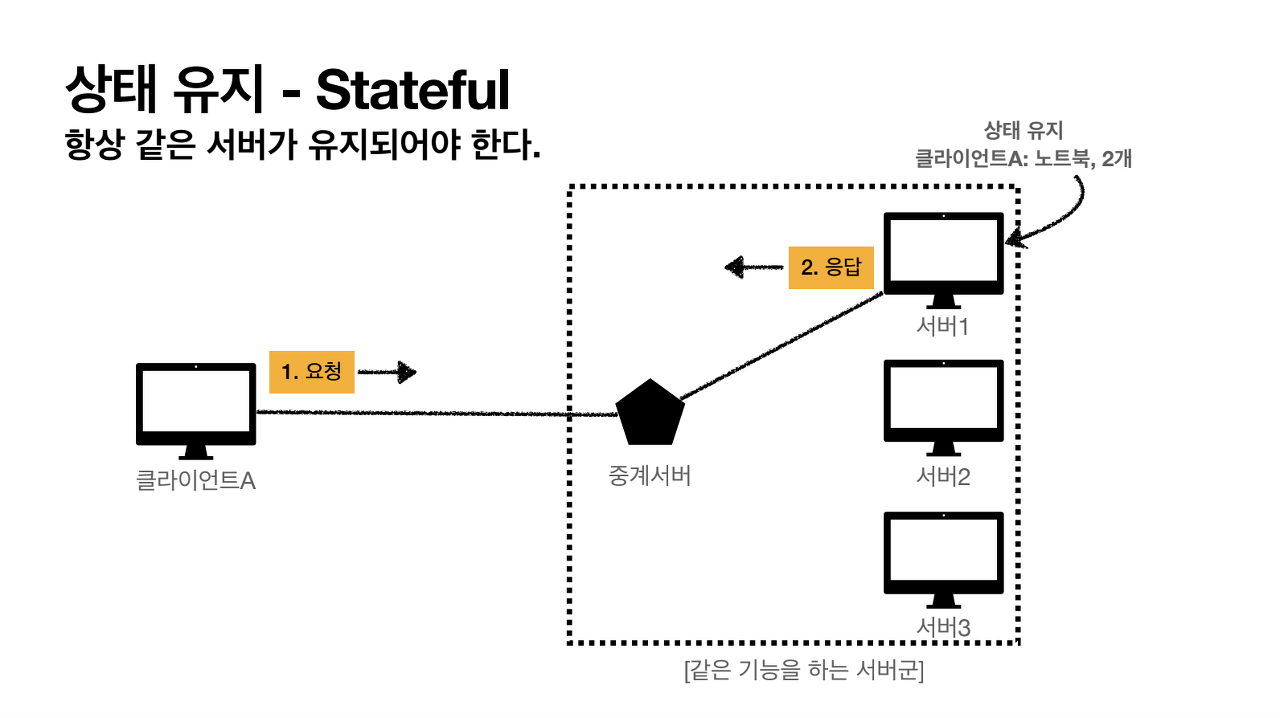

서버가 클라이언트의 상태를 보존하는 것이다. 대표적인 예로 홈페이지에서 회원 로그인을 하면 페이지를 옮겨가도 서버는 클라이언트의 상태를 보존하기 때문에 해당 클라이언트에서 회원인지 인지한다. 하지만 만약 중간에 서버에서 장애가 발생하면 클라이언트는 처음부터 다시 작업을 요청해야 한다. 그래서 서버가 바뀔때마다 클라이언트의 내용을 일일이 기록해서 상태를 유지해야 하는데 이를 구현하기에는 쉽지 않다.
(2) Stateless (무상태)

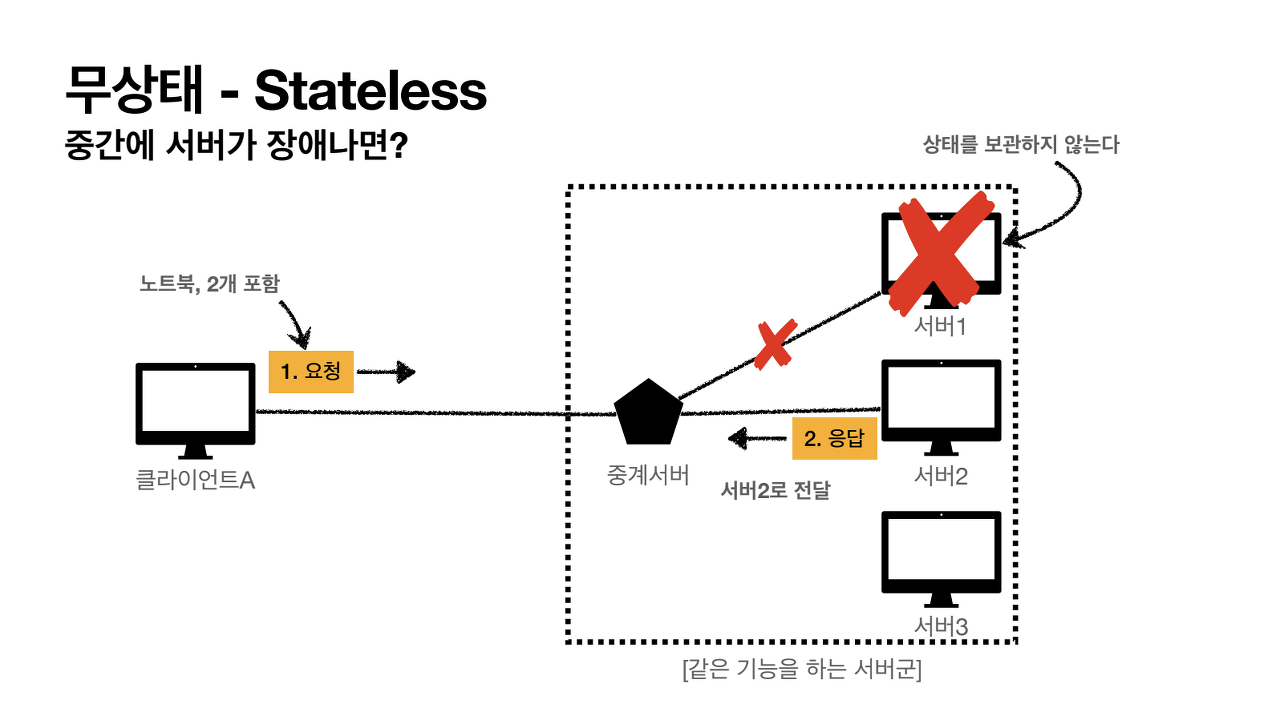
서버가 클라이언트의 상태를 보존하지 않는다. 홈페이지에서 회원 로그인을 하고 페이지를 옮겼는데 또 로그인을 하라는 페이지가 뜬다. 서버는 클라이언트의 상태를 보존하지 않기 때문에 그 클라이언트가 회원인지 모르기 때문이다. 따라서 무상태 환경에서는 회원 정보를 서버가 아닌 클라이언트가 토큰 형태로 들고 있으면서 서버와 통신할 때마다 실어 보내서 인증을 받는 형식인 것이다.
이렇게 무상태는 클라이언트가 상태 정보를 갖고 있는 것이기 때문에 아무 서버에나 호출해도 되기 때문에 서버의 Scale-Out에 유리하다. 하지만 상태유지보다 데이터를 많이 사용한다는 단점이 있다.
HTTP 비연결성 (Connectionless)
HTTP는 기본적으로 연결이 유지되지 않는 모델이다. 서버와 클라이언트의 Connection 연결을 유지하지 않는다는 의미이다.
1시간동안 수천명 이상이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 적다. 예를 들어 웹 브라우저의 검색페이지에서 검색버튼만 연타하면서 이용하지는 않는 것처럼 말이다.
우리는 이러한 비연결성 특성 때문에 서버 자원을 효율적으로 사용할 수 있다.
Stateless와 Connectionless의 차이점?
- Stateless (무상태성): 필요한 상태에 대한 정보를 클라이언트에서 직접 가져오기 때문에 클라이언트의 요청에 어느 서버가 응답해도 전혀 상관이 없다. 따라서, 클라이언트의 요청이 대폭 증가하면 서버를 증설해서 해결할 수 있다.
- Connectionless (비연결성): 클라이언트가 서버에 요청을 하고 서버로부터 응답을 받게 되면 즉각적으로 TCP/IP 연결을 끊어서 연결을 유지하지 않음으로써 서버의 자원을 효율적으로 관리하고 수 많은 클라이언트의 요청에 대응할 수 있게 된다.
다시 말해서 무상태성은 클라이언트와 서버 간의 상태 정보를 들고 있지 않아서 클라이언트가 상태 정보를 일일이 HTTP에 실어 요청해야 되는 것을 말하고, 비연결성은 클라이언트와 서버 간에 네트워크 연결이 끊어져 단절된다고 생각하면 될 것 같다.
연결을 유지하는 모델
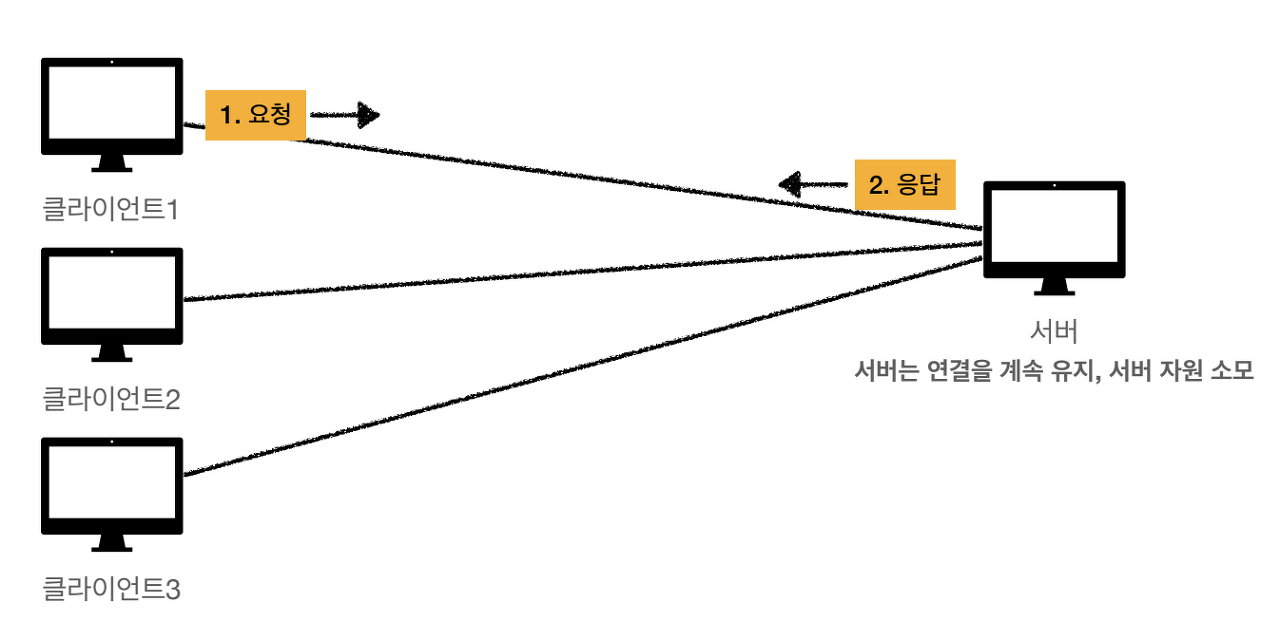
여러 클라이언트에서 서버로 응답을 요청하게 되면 서버에서는 요청이 들어온 클라이언트마다 연결을 유지해서 상태를 저장한다. 클라이언트가 많아질수록 연결을 유지하는 서버의 자원이 계속 소모된다는 단점이 있다. 이런 단점으로 인해 HTTP는 기본적으로 연결을 유지하지 않는 모델이다.
연결을 유지하지 않는 모델

클라이언트가 요청할 때마다 서버는 응답만 보내주고 연결을 종료하기 때문에 서버가 최소한의 자원으로 유지할 수 있다. 하지만 클라이언트가 지속적으로 연결을 끊는다는 것은 TCP/IP 연결을 매번 새롭게 맺어야 한다는 것이다.
다시 말해, TCP 3-way handshake를 매번 해야하고, 이는 시간이 소요된다. 그래서 HTTP에서는 이런 문제를 지속 연결(Persistent Connections)로 문제를 해결하고 있다. 그리고 참고로 HTTP 2,3버전에서는 더 많은 최적화가 이루어지고 있다.
Connectionless (비연결성) 의 한계 - HTTP 초기

HTTP 초기에는 연결하고 종료하고 많은 낭비가 발생했다. 웹 브라우저로 사이트를 요청하면 HTML 뿐만 아니라 자바스크립트, css, 추가 이미지 등 수많은 자원이 함께 다운로드가 되는데 새로 연결을 맺을 때마다 TCP Handshake가 발생한다는 문제가 있음.
그래서 HTTP 초기에는 모든 자료에 대해서 비연결성으로 각각의 자원에 대해 연결/응답/종료를 반복하다보니 대략적으로 1초가량 소모되었다.
Connectionless (비연결성) 극복 - HTTP 지속 연결 (Persistent Connections)

클라이언트에서는 서버와 소켓 연결을 한 다음 필요한 자원을 요청하고 응답으로 다운로드 받는다. 소켓 연결을 일정시간 동안 유지함으로써 필요한 자원들을 모두 다운받을 때 까지 연결이 종료되지 않고 요청/응답이 반복된 뒤에 종료가 된다.
HTTP Message
HTTP 메세지 구조

HTTP 메세지는 기본적으로 위에서부터 시작 라인(start-line), 헤더(header), 공백 라인(empty-line) 그리고 바디(message body)로 이루어져 있다.
필자는 empty-line이 꼭 있어야 하나 많이 궁금했는데 꼭 필요하다고 한다. HTTP 메세지 값을 구분하기 위한 라인이기 때문에 단순히 보기 편하다는 것을 넘어서 반드시 필요하다고 한다.
[시작 라인 (Start-Line)]
시작 라인은 크게 Request-Line과 Status-Line으로 구분된다. 구체적으로 요청 메세지인지 응답 메세지인지에 따라서 request/status로 내용의 구성이 변경된다.
[요청 메세지 (Request Message)]
요청 메세지에서는 시작라인이 Request-Line이다. 이 때 Request-Line의 구조는 method (공백) request-target (공백) HTTP-Version (엔터)로 구분된다. 요청 메세지에 들어갈 수 있는 HTTP Method는 GET, POST, PUT, DELETE 등 여러가지가 있고 요청 대상(request-target)은 절대 경로와 쿼리를 조합해서 작성할 수 있다. 또한, 요청 메세지 시작 라인에는 HTTP 버전 정보가 함께 들어간다.
[응답 메세지 (Response Message)]
응답 메세지는 시작라인이 Status-Line이다. 이 때 Status-Line의 구조는 HTTP-Version (공백) Status-Code (공백) Response-Phrase (엔터)로 구분된다. HTTP Status Code에서는 요청 성공 혹은 실패를 나타낸다. 보통 200번대는 성공, 400번대는 클라이언트 요청 오류, 500번대는 서버 내부 오류라고 한다. 그리고 Response-Phrase는 사람이 이해할 수 있는 짧은 상태 코드를 읽을 수 있는 글이라고 한다.
[헤더 (Header)]

HTTP 헤더는 HTTP 전송에 필요한 모든 부가 정보를 담기 위해서 생성된다. 예를 들어, 메세지의 바디 내용, 크기, 압축, 인증, 요청 클라이언트의 정보 등 여러 부가적인 정보가 들어간다. 표준 헤더들이 많은데 필요에 따라 임의 헤더도 추가할 수 있다.
[메시지 바디 (Message Body)]
메시지 바디에는 실제로 전송할 데이터를 담고 있다. 예를 들어 HTML 문서, 이미지, 영상, JSON 등 Byte로 표현할 수 있는 모든 데이터가 바디가 될 수 있다.
* 이미지 출처는 강의에서 가져왔음을 표시합니다 *
참고 자료
- https://www.inflearn.com/course/http-%EC%9B%B9-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC
모든 개발자를 위한 HTTP 웹 기본 지식 - 인프런 | 강의
실무에 꼭 필요한 HTTP 핵심 기능과 올바른 HTTP API 설계 방법을 학습합니다., [사진] 📣 확인해주세요!본 강의는 자바 스프링 완전 정복 시리즈의 세 번째 강의입니다. 우아한형제들 최연소 기술
www.inflearn.com
🌐 HTTP는 무엇일까요? - 기본 핵심 요약 총정리
HTTP 란? - Hyper Text Transfer Protocol HTTP는 서버와 클라이언트가 서로 데이터를 주고받기 위해 사용되는 통신 규약을 말일컷는다. 웹문서간에 링크를 통해 연결할 수 있는 프로토콜이며, 문서뿐 아니
inpa.tistory.com
'CS지식 > Network' 카테고리의 다른 글
| [Network] 클라이언트에서 서버로 데이터 전송 (1) | 2023.12.06 |
|---|---|
| [Network] HTTP Methods (0) | 2023.12.04 |
| [Network] URI + 웹 브라우저 요청 흐름 (1) | 2023.11.30 |
| [Network] TCP와 UDP 그리고 PORT와 DNS (2) | 2023.11.29 |
| [Network] 인터넷 프로토콜 (IP) (2) | 2023.11.29 |



